To complete this tutorial, you will need the following:
- IBM SPSS® Modeler® 16
- R 2.15.2 (Free) –> R-2.15.2 for Windows (32/64 bit)
- IBM SPSS® Modeler® – Essentials for R Plugin (Free)
- R Studio (Free) –> Download
Visit https://apps.twitter.com and sign in with your Twitter credentials.
Click the ' Create New App' button near the top. A new page with the Create an application form (Figure A) requires basic information about your application.
Figure A
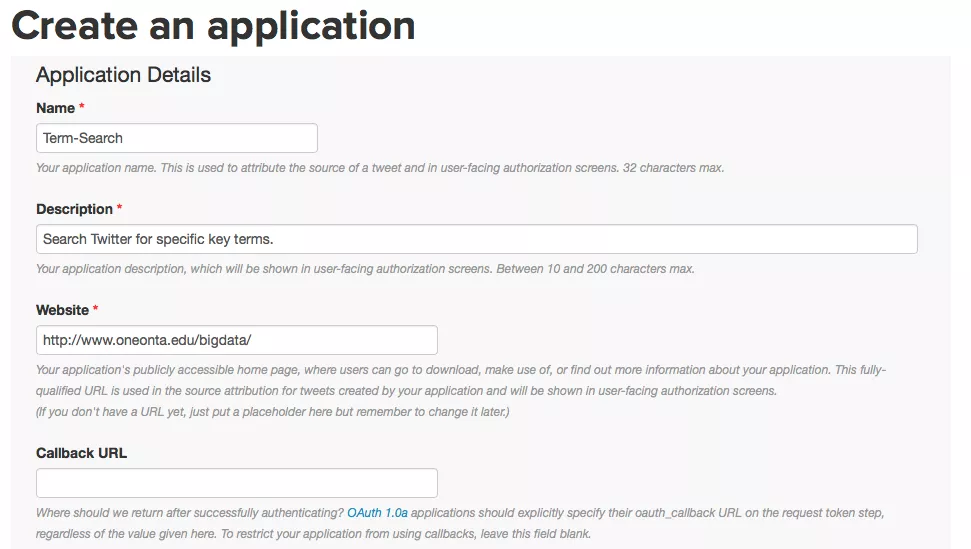
- In the Name field, name your application in 32 characters or fewer. This name is presented to users when they are prompted to authorize your application to access their Twitter information. In the Description field, describe your application in 10 to 200 characters. Again, this is presented to users on authorization screens.
- In the Website field, give a URL that points the user back to your application, where they can download it or find out more information. As with Name and Description, this field is presented on user-facing authorization screens.
- The Callback URL field can specify the URL were Twitter should redirect after successful authorization. It is best to leave this field blank and to explicitly specify the callback URL at authorization time.
- The last part of the form is a Developer Agreement which you must agree to before your app can be created.
A page will now appear verifying the creation of the app. Click the Keys and Access Tokens link (Figure B) to view the keys you will need to use in the next step of writing the script to harvest tweets. These keys are shown in Figure C.
Figure B
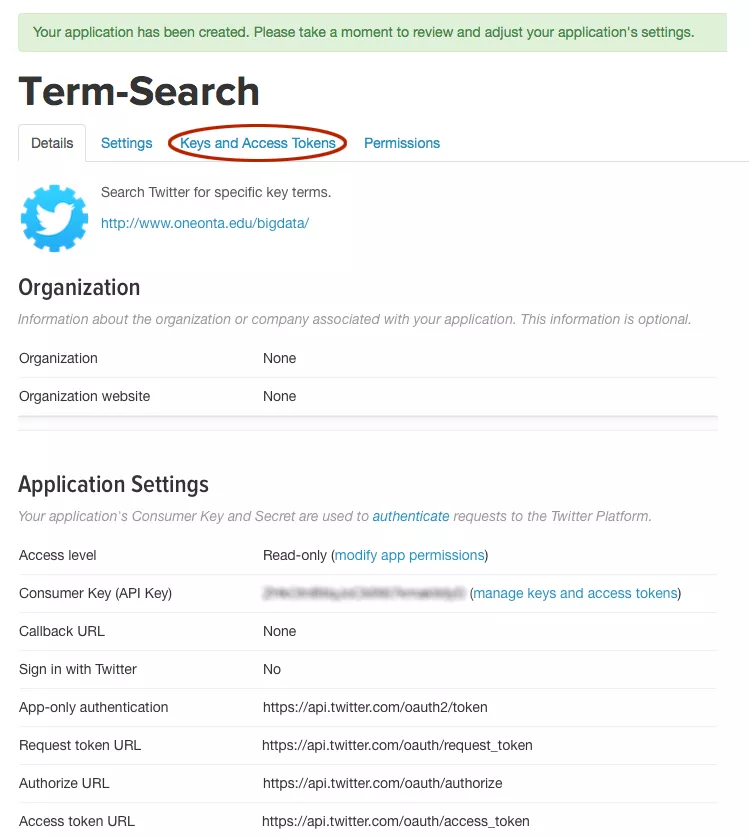
Figure C
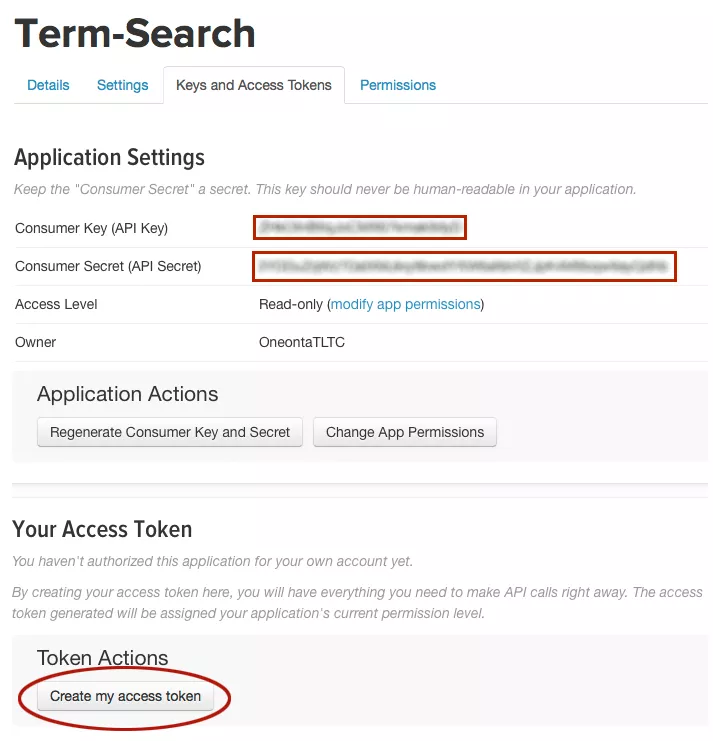
The last thing to do is click the 'Create my access token' button as shown in Figure C. Even though doing so is necessary to completing this process, these tokens won't be needed in this tutorial. You are now ready to move to Step 2.
In order to gather any kind of Twitter data, you need to create a process by which to communicate with Twitter and tell it what information you are looking for. This process is referred to as a Twitter App.
Each time your script is run to harvest data, Twitter directs you to a specific URL to acquire an authentication PIN. Unfortunately IBM SPSS Modeler 16 does not allow a process to be paused to provide this PIN. In order to accommodate this, Twitter authentication can be run once and saved to a file for later use.
IMPORTANT: Since a Twitter App will only return a limited number of results during a 24 hour period, this file should not be shared for public use.
Step 2: Saving Twitter App Authentication
library(twitteR)
library(ROAuth)
download.file(url="http://curl.haxx.se/ca/cacert.pem", destfile="cacert.pem")
reqURL <- "https://api.twitter.com/oauth/request_token"
accessURL <- "https://api.twitter.com/oauth/access_token"
authURL <- "https://api.twitter.com/oauth/authorize"
apiKey <- "xxxxxxxxxxxxxxxxxxxxxxxxx"
apiSecret <- "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
twitCred <- OAuthFactory$new(
consumerKey = apiKey,
consumerSecret = apiSecret,
requestURL = reqURL,
accessURL = accessURL,
authURL = authURL
)
twitCred$handshake(
cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl")
)
registerTwitterOAuth(twitCred)
save(twitCred, file="TwitterSearch.RData")
Each time your script is run to harvest data, Twitter directs you to a specific URL to acquire an authentication PIN. Unfortunately IBM SPSS Modeler 16 does not allow a process to be paused to provide this PIN. In order to accommodate this, Twitter authentication can be run once and saved to a file for later use.
IMPORTANT: Since a Twitter App will only return a limited number of results during a 24 hour period, this file should not be shared for public use.
It's important to debug any R code you will be embedding in IBM® SPSS® Modeler 16 using R or R Studio. Even though Modeler has an output console that displays R code and any messages that result from running it, the R tools have a more robust interface for catching and resolving errors.
Step 3: Debugging R Script to Harvest Tweets
if (require('twitteR')==FALSE) {
install.packages(twitteR)
}
library('twitteR')
home.dir <- 'c:/Users/mosemadl.ONEONTA/My Documents/BigData/R/'
load(file=paste(home.dir, "TermSearch.RData", sep=""))
registerTwitterOAuth(twitCred)
q.col <- 'fracking'
n.col <- 100
local.tweets <- function(x, y) {
tweets <- searchTwitter(q.col, n=n.col, cainfo=paste(home.dir,
"cacert.pem", sep=""))
dataTweets = twListToDF(tweets)
data <- data.frame(dataTweets$text, dataTweets$created,
dataTweets$screenName, dataTweets$id)
names(data)[names(data)=="dataTweets.text"] <- "text"
names(data)[names(data)=="dataTweets.created"] <- "created"
names(data)[names(data)=="dataTweets.screenName"] <- "screenName"
names(data)[names(data)=="dataTweets.id"] <- "id"
write.table(data, file=paste(home.dir,"ModTweets.csv", sep=""),
append=FALSE, sep="\t ", col.names=TRUE)
print(data)
}
modelerData <- data.frame(q.col, n.col)
tmp.output <- t(apply(modelerData, 2, function(x, y) local.tweets(x, y)))
data.output <- unlist(tmp.output)
modelerData <- cbind(modelerData, data.output)
It's important to debug any R code you will be embedding in IBM® SPSS® Modeler 16 using R or R Studio. Even though Modeler has an output console that displays R code and any messages that result from running it, the R tools have a more robust interface for catching and resolving errors.
Building an IBM SPSS Modeler stream using R code requires minor modification to the script. The results generated can directly be used to produce interesting representations of the data collected.
Step 4: Building an IBM® SPSS® Modeler Stream
if (require('twitteR')==FALSE) {
install.packages(twitteR)
}
library('twitteR')
home.dir <- 'c:/Users/mosemadl.ONEONTA/My Documents/BigData/R/'
load(file=paste(home.dir, "TermSearch.RData", sep=""))
registerTwitterOAuth(twitCred)
q.col <- modelerData$q
n.col <- modelerData$n
tweets <- searchTwitter(as.character(q.col), n=n.col,
cainfo=paste(home.dir, "cacert.pem", sep=""))
dataTweets = twListToDF(tweets)
data <- data.frame(dataTweets$text, dataTweets$created,
dataTweets$screenName, dataTweets$id)
names(data)[names(data)=="dataTweets.text"] <- "text"
names(data)[names(data)=="dataTweets.created"] <- "created"
names(data)[names(data)=="dataTweets.screenName"] <- "screenName"
names(data)[names(data)=="dataTweets.id"] <- "id"
write.csv(data, file=paste(home.dir,"ModTweets.csv", sep=""),
append=FALSE, row.names=FALSE, sep=",")
print(data)
modelerData <- cbind(modelerData,data$text)
var1 <- c(fieldName="Tweets",fieldLabel="",fieldStorage="string",
fieldMeasure="",fieldFormat="",fieldRole="")
modelerDataModel <- data.frame(modelerDataModel, var1)
Building an IBM SPSS Modeler stream using R code requires minor modification to the script. The results generated can directly be used to produce interesting visual representations of the data collected.
Creative Commons
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.